Trilha ARQUITETURA DE DADOS
Nos dias de hoje com a infinidade de tecnologias de armazenamento de dados disponíveis, é imprescindível que tenhamos uma arquitetura bem definida para tirarmos melhor proveito dos dados.
Utilizar um conceito ou uma classe específica de banco de dados ou armazenamento para a aplicação dependendo do que ela se trata!
Data
Quinta-feira, 25 de Março de 2021
09h às 19h (somente ao vivo)
Investimento
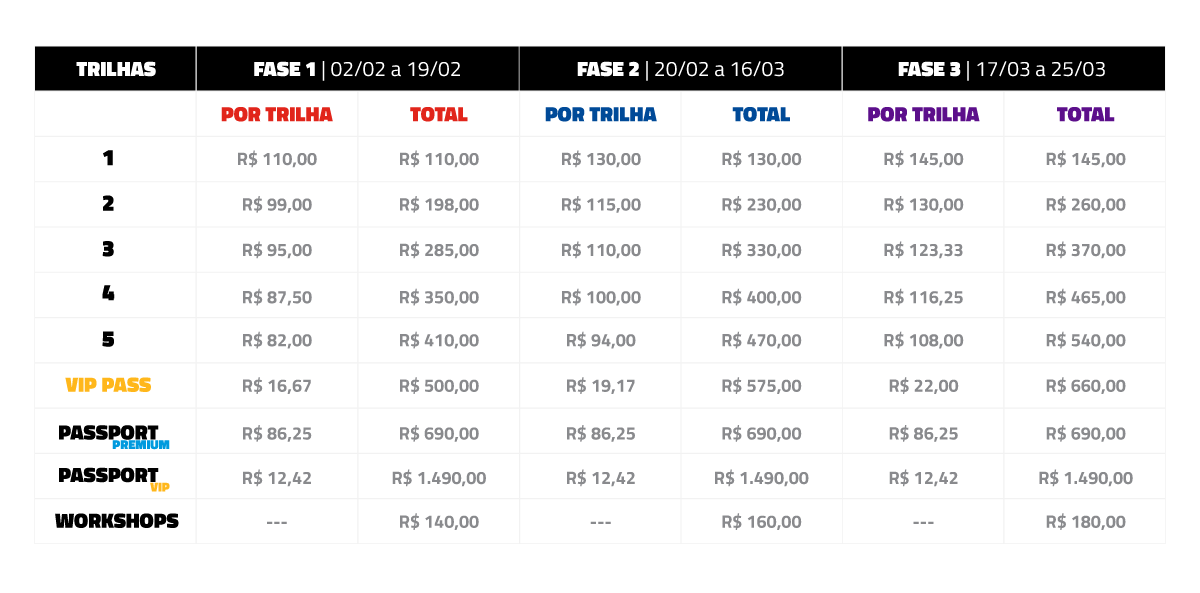
1 trilha: De R$ 145 por R$ 110
2 trilhas: De R$ 290 por R$ 198
3 trilhas: De R$ 435 por R$ 285
* preço válido até 19/02
1 trilha: De R$ 145 por R$ 130
2 trilhas: De R$ 290 por R$ 230
3 trilhas: De R$ 435 por R$ 330
* preço válido até 16/03
1 trilha: R$ 145
2 trilhas: De R$ 290 por R$ 260
3 trilhas: De R$ 435 por R$ 370
* preço válido até 25/03
Como se inscrever





.png)













 Advaldo Mesquita Moreira Junior
Advaldo Mesquita Moreira Junior
 Rodrigo Crespi
Rodrigo Crespi