A Trilha de Engenharia de Dados é um espaço dedicado à exploração dos desafios, soluções e inovações que moldam o mundo dos dados modernos. No mundo digital atual, onde a quantidade de dados cresce exponencialmente, a capacidade de processar, armazenar e extrair insights valiosos desses dados é uma competência fundamental. Se você é desenvolvedor, engenheiro de dados, arquiteto, cientista de dados ou entusiasta do setor, junte-se a nós nessa jornada de aprendizado e descoberta. Independentemente de você estar dando seus primeiros passos na área ou ser um veterano experimentado, esta trilha oferecerá insights valiosos, conexões inestimáveis e inspiração para impulsionar sua carreira e projetos.
Sexta-feira, 24 de Março de 2023
09h às 19h
Centro Cultural Cais do Sertão
Av. Alfredo Lisboa, s/n / armazém 10
Bairro do Recife Recife - PE
ACESSO PRESENCIAL OU REMOTO COM TRANSMISSÃO ONLINE
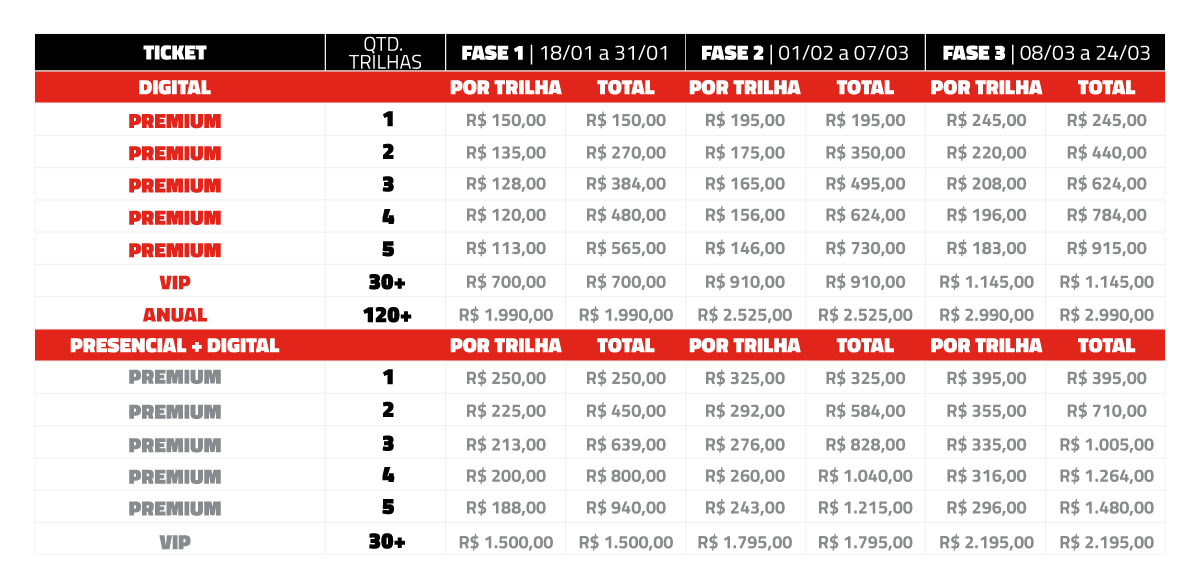
Valores para participação online:
1 trilha: de R$ 245 por R$ 150
2 trilhas: de R$ 440 por R$ 270
3 trilhas: de R$ 624 por R$ 384
* aproveite maior desconto até 31/01,
veja tabela completa
Valores para participação online:
1 trilha: de R$ 245 por R$ 195
2 trilhas: de R$ 440 por R$ 350
3 trilhas: de R$ 624 por R$ 495
* preço válido até 07/03,
veja tabela completa
Valores para participação online:
1 trilha: R$ 245
2 trilhas: R$ 440
3 trilhas: R$ 624
* preço válido até 24/03,
veja tabela completa
Valores para participação híbrida:
1 trilha: de R$ 395 por R$ 250
2 trilhas: de R$ 710 por R$ 450
3 trilhas: de R$ 1.005 por R$ 639
Valores para participação híbrida:
1 trilha: de R$ 395 por R$ 325
2 trilhas: de R$ 710 por R$ 584
3 trilhas: de R$ 1.005 por R$ 828
Valores para participação híbrida:
1 trilha: R$ 395
2 trilhas: R$ 710
3 trilhas: R$ 1.005
| Horário | Conteúdo |
|---|---|
| 07:45 às 08:55 | Recepção dos Participantes |
| 09:00 às 09:40 | Abertura do evento e mini keynotes |
| 09:45 às 10:00 |

A MySQL HeatWave Overview for Every DeveloperHerbert MenezesIn this session, you'll learn how MySQL HeatWave provides a single database service for transaction processing, analytics, machine learning, and data lake applications. It eliminates the complexity of ETL operations and existing MySQL applications run without any changes. MySQL HeatWave provides the best price-performance among competing offerings and is offered on multiple clouds.

|
| Horário | Conteúdo |
|---|---|
| 10:00 às 10:05 |
Abertura da trilha pela coordenação
Aqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
| 10:05 às 10:40 |
Como construímos uma plataforma de dados eficiente aplicando boas práticasDiogo FalcãoLidar com problemas de dados em uma empresa de alta tecnologia pode ser uma tarefa complexa, mas é essencial para garantir o sucesso dos negócios. À medida que a quantidade de dados aumenta, é importante ter sistemas para gerenciá-los e analisá-los com eficácia. Porém, um grande desafio consiste em como criar e expandir a plataforma de dados sem aumentar na mesma proporção, os custos e principalmente com um time enxuto. Nesta apresentação iremos ver como a VTEX conseguiu criar uma plataforma de dados do 0 e como aplicar as melhores práticas para um crescimento rápido e sustentável. 
|
| 10:45 às 11:20 |
Ciclo de vida da Série TemporalVagner PontesEsta palestra demonstra uma solução prática implementada para endereçar as capacidades requeridas para gerenciar dados no formato de séries temporais. Esta é uma aplicação real frequentemente encontrada nas empresas líderes no segmento de energia e bebidas. Como o volume de dados gerados a cada ano aumenta exponencialmente, o mercado de banco de dados tem uma necessidade de fornecer ferramentas e serviços que permitem aos usuários gerenciar todo o ciclo de vida de uma série temporal: coletar, armazenar, gerenciar e analisar dados de maneiras cada vez mais inovadoras Ao final desta palestra o participante terá entendimento para implementar uma solução de dados para séries temporais. 
|
| 11:25 às 11:40 |
Nós, robôs: uma história sobre Open Source e IARicardo Martinelli de OliveiraPara levar a tecnologia a um novo patamar, temos que levar em conta o que fizemos no passado. A evolução é natural, mas a colaboração é um motor principal para evoluir mais e melhor. Com a IA não é diferente. Preparem-se para ouvir uma breve história sobre o que podemos fazer em colaboração, através do Open Source, para atingir patamares mais elevados.

|
| 11:45 às 12:20 |
Mentalidade Data DrivenMarcos FreitasAbordar de forma ampla os pilares de uma mentalidade Data Driven, tanto para as pessoas quanto para as empresas, com sugestões de caminhos para avançar neste tema. 
|
| 12:25 às 13:55 |
Intervalo para almoço
Uma excelente oportunidade de todas as pessoas no evento interagirem e trocarem ideias, colaboradores, empresas patrocinadoras e apoiadoras, palestrantes e coordenadores. |
| 14:05 às 14:40 |
Lakehouse a arquitetura de dados do futuro. Como o ecossistema do Databricks nos permite fazer mais com menos.Thiago Henrique Lopes / Guilherme Felipe SimãoOs Data Warehouse vem cumprindo bem seu papel desde o final dos anos 80, mas eles não permitem armazenar dados não estruturados, os Data Lakes permitem isso, mas não tem suporte a transações ACID e não permitem trabalho em esquemas, pra solucionar esses problemas surgiu o Lakehouse, uma arquitetura open source, que permitem armazenamento em storages multi-cloud com computação distribuída, garantia de transações ACID, aplicação de segurança e governança dos esquemas, armazenamento de diferentes tipos de arquivos inclusive não estruturados, suporte a BI e Data Science, e muito mais. Junte-se a nós e entenda essa arquitetura que o levará a um outro nível 

|
| 14:45 às 15:20 |
Detectando e mascarando dados sensíveis na AWSThiago da Hora / Carolina Junqueira FerreiraNesta sessão, vamos falar sobre o impacto da privacidade em arquiteturas de dados, como construir um pipeline de dados orientado a eventos e serverless na AWS e com a funcionalidade de identificar dados sensíveis como CPF, RG, CNPJ, CEP e Telefone (ou qualquer outro padrãom, como dados de saúde) através de serviços no-code. Também aplicaremos técnicas de mascaramento irreversível e reversível nos dados sensíveis. 

|
| 15:25 às 16:00 |
Como produtizar um código Spark com Airflow e EMR Serverless?Helder GuedesCom uma abordagem prática e objetiva, essa palestra apresenta uma estratégia para produtizar um código Spark, em combinação com o Apache Airflow e EMR Serverless. Serão apresentados exemplos desde a configuração inicial, até a execução de jobs Spark, de modo a compreender como estas tecnologias podem auxiliar o dia-a-dia do Engenheiro de Dados. 
|
| 16:05 às 16:40 |
Versatilidade no processo de ETL com Kettle e RabbitMQNadja Carolina Santos De OliveiraA presente sessão trará um exemplo real de associação de ETL e Fila, muito utilizados por ambientes institucionais que buscam apresentar informações em tempo real. Vou apresentar uma solução de ETL utilizada em um projeto de finanças que exigiu versatilidade para diminuir o tempo de resposta e automatizar o processo de atualização das informações. Serão abordados conceitos introdutórios de fila e sua utilização por algumas vertentes, além de sua composição para o processo de ETL, representada pela ferramenta Kettle. Com conceitos de extração, transformação e carga de dados, essenciais ao uso do processo de ETL, juntamente com o conceito de fila implementado no RabbitM. 
|
| 16:45 às 17:15 |
Networking e Visitação a Stands
Intervalo para fazer networking e conhecer os estandes do evento. |
| 17:20 às 18:20 |
A era pós Engenharia de Dados na transformação dos negócios digitais!Helga Jinzenji / Cesar Augusto de Carvalho / Vinicius Cardoso Garcia / Filipe AvillaPainel desta Trilha




|
| 18:20 às 18:25 |
Encerramento da trilha
Os coordenadores fazem um breve encerramento com agradecimentos. |
| Horário | Conteúdo |
|---|---|
| 18:25 às 19:00 |
Encerramento
Após a apresentação de resultados do dia, no palco da Stadium, muitos sorteios fecharão o dia. |

























.png) Leandro Domingues
Leandro Domingues

 Lourenço Taborda
Lourenço Taborda
 Virginia Heimann
Virginia Heimann
.png)