TRILHA ENGENHARIA DE DADOS
Diamond Trilha

Apoio Trilha


O que é uma trilha?
A trilha é um evento híbrido, presencial em São Paulo e remoto na sua casa, que tem a duração de um dia inteiro com sete palestras e um painel de discussão.
Data e Local
Quarta-feira, 20 de Setembro de 2023
09h às 19h
ProMagno
Avenida Professora Ida Kolb - 513 /
Jardim das Laranjeiras
São Paulo -
SP
ACESSO PRESENCIAL OU REMOTO COM TRANSMISSÃO ONLINE
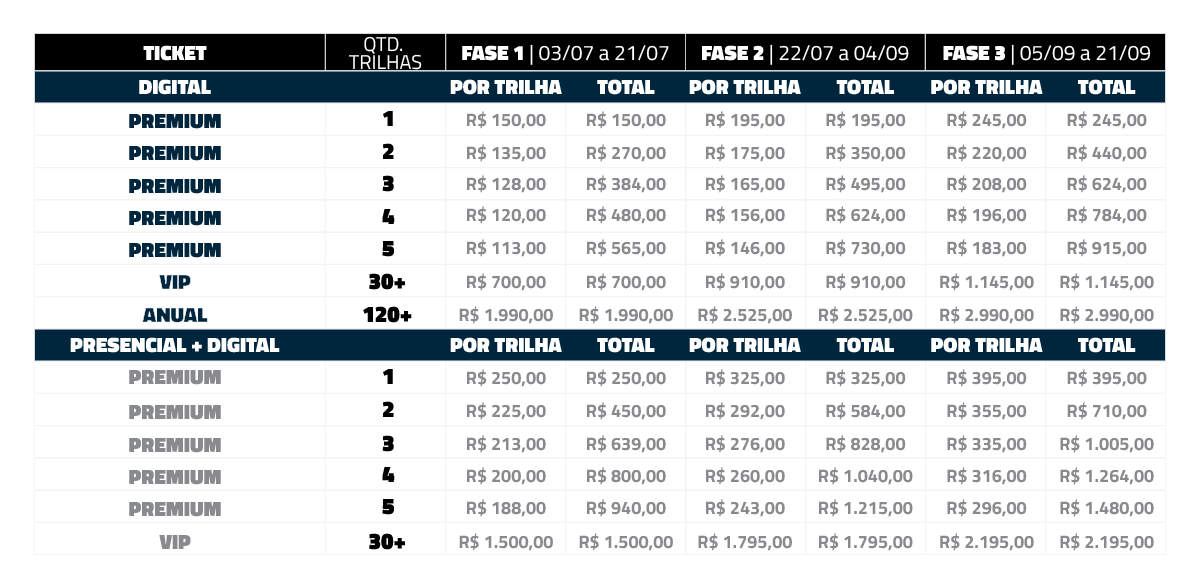
Investimento
Inscrição online
1 trilha:
de R$ 245
por R$ 150
Inscrição online
1 trilha:
de R$ 245
por R$ 195
Inscrição online
1 trilha: R$ 245
Inscrição híbrida (presencial + online)
1 trilha:
de R$ 395
por R$ 250
Inscrição híbrida (presencial + online)
1 trilha:
de R$ 395
por R$ 325
Inscrição híbrida (presencial + online)
1 trilha: R$ 395
Promoções
Inscrição online
2 trilhas: R$ 440
3 trilhas: R$ 624
Inscrição híbrida (presencial + online)
2 trilhas: R$ 710
3 trilhas: R$ 1.005
Esta trilha pertence à área Dados e I.A.
Confira as trilhas relacionadas:
Programação / Palestras Time Zone: GMT-3
| Programação Stadium: |
|---|
|
A partir das 07:30h Credenciamento |
|
09:00 às 10:00 Abertura do evento e mini keynotes |
| Programação desta Trilha: |
|---|
|
10:10 às 10:25 Abertura da trilha pela coordenaçãoAqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
|
10:30 às 11:05 Data lakes, lake houses e data mesh: O que, por que, e como? - Na prática!Erika NagamineTrabalhar com grandes volumetrias de dados possibilita retirar insights de seus dados e permitindo o compartilhamento entre diferentes pessoas. Além disso, devemos pensar numa arquitetura de dados aberta e extensível que suporte uma variedade de casos de uso. Como você pode usar data lakes, lakehouses e data mesh como principais abordagens para criar uma arquitetura de dados moderna e bem arquitetada na AWS - Na prática 
|
|
11:15 às 11:50 Porque é tão difícil emplacar uma cultura de dados?Jhonathan de Souza SoaresDescubra os desafios e soluções para criar uma área de dados eficaz com baixo orçamento nesta palestra informativa. Vamos explorar a importância da engenharia de dados, os obstáculos comuns na criação de uma área de dados e estratégias práticas para superar esses desafios. Aprenda como maximizar o uso de ferramentas open source, cultivar talentos internos e criar uma cultura de dados robusta, mesmo com recursos limitados. 
|
|
11:55 às 12:30 Descubra o poder da arquitetura Lakehouse com Delta Lake e Azure Databricks!Guilherme Felipe Simão / Thiago Henrique LopesExploraremos a fascinante área da engenharia de dados e como a combinação do Delta Lake com o Databricks pode impulsionar sua organização para o próximo nível. Conheça as vantagens dessa arquitetura inovadora, que oferece o melhor dos mundos do data lake e do data warehouse. Aprenda como o Delta Lake fornece transações ACID, governança e confiabilidade em seus dados para cargas de trabalho de Big Data, enquanto o Databricks permite gerenciar e processar os dados em larga escala. Prepare-se para mergulhar em um ecossistema poderoso que simplifica suas operações de dados e impulsiona a inovação. Junte-se a nós nesta jornada e desbloqueie todo o potencial da sua infraestrutura de dados. 

|
|
12:40 às 14:05 Intervalo para almoçoUma excelente oportunidade de todas as pessoas no evento interagirem e trocarem ideias, colaboradores, empresas patrocinadoras e apoiadoras, palestrantes e coordenadores. |
|
14:05 às 14:15 Abertura da trilha pela coordenaçãoAqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
|
14:15 às 14:50 Bancos de Dados Distribuído na Prática! Como funciona o CockroachDB.William Lino OliveiraUma das maiores limitações dos bancos de dados relacionais tradicionais é a limitação de escalar escrita de forma horizontal, isso acaba impedindo que façamos diversas operações administrativas na camada de bancos de dados sem impactar a aplicação. Nesta sessão vou mostrar na prática como um dos bancos de dados distribuídos mais utilizados do mundo, o CockroachDB, entrega essa capacidade de escalar horizontalmente e em multi-cloud aumentando assim a estabilidade e escalabilidade de sua aplicação e tudo isso na prática! 
|
|
14:55 às 15:30 
Princípios da Modelagem de Dados em MongoDBLourenço Taborda / Felipe CabralCriar um esquema para um banco de dados relacional é um processo simples. Projetar um esquema para um aplicativo MongoDB pode parecer um pouco mais desafiador. No entanto, não precisa ser difícil se você seguir os princípios fundamentais de modelagem de dados para MongoDB. Esta palestra abordará esses princípios de modelagem de dados e as dicas de modelagem para lidar com o mundo em constante mudança da tecnologia de dados, como novos recursos do MongoDB, evolução do hardware, data lakes e o crescente impacto da análise de dados. 

|
|
15:35 às 16:10 Vector Search: A próxima grande revolução na corrida da IAAlex SalgadoMergulhamos no mundo emergente dos bancos de dados e busca vetoriais, a próxima grande revolução na IA. Descobrimos como essa tecnologia está mudando o jogo ao lidar com o eterno desafio dos dados não estruturados, que compõem até 80% dos dados armazenados globalmente. Abordamos como esses bancos de dados podem remodelar nossa interação com dispositivos e melhorar a produtividade em uma ampla gama de tarefas. Além disso, exploramos a relevância desses bancos de dados para a IA generativa, uma área que já despertou grande interesse no mundo da tecnologia. Com exemplos práticos, vamos lançar luz sobre essa tecnologia disruptiva, prevendo suas implicações futuras no cenário da IA. 
|
|
16:15 às 16:50 Escalando a qualidade de dados com Great Expectations e Spark no Modern Data StackCícero MouraO Modern Data Stack é uma combinação de tecnologias que ajuda as empresas a gerenciar seus dados de forma eficiente e rápida, onde é composto por conceitos como Data Mesh, Data Catalog, Data Observability e outros, a qualidade dos dados é fundamental em todos eles. Nesta palestra, será apresentado o Great Expectations, uma ferramenta open source para aplicar testes de qualidade em dados que pode ser usada em conjunto com Spark e AWS. Discutiremos casos de uso práticos sobre arquiteturas de como aplicar qualidade em grandes conjuntos de dados, assim possibilitar insights para ter qualidade de dados dentro das organizações e resolver problemas reais de negócios, agregando valor aos clientes. 
|
|
16:55 às 17:25 Networking e Visitação a StandsIntervalo para fazer networking e conhecer os estandes do evento. |
|
17:30 às 18:30 Dados: Carreira & MercadoJhonathan de Souza Soares / Cintia Silvestre / Camila Alves de Souza QueirozPainel de Discussão desta Trilha


|
| Programação da Stadium no final do dia: |
|---|
|
18:35 às 19:05 Encerramento da trilhaOs coordenadores fazem um breve encerramento com agradecimentos. |
.png) Leandro Domingues
Leandro Domingues
 Sulamita Mara Dantas
Sulamita Mara Dantas
 Neylson Crepalde
Neylson Crepalde
 Anice Almeida Alexandre
Anice Almeida Alexandre




















































.png)