Segundo a empresa de consultoria Gartner, atualmente, mais de 80% dos líderes tomam decisões com auxílio de dados, melhorando suas capacidades de justificar decisões estratégicas e aumentando a assertividade do negócio. Os dados que auxiliam essa tomada de decisão são dos mais diversos formatos e podem vir das mais diversas origens. Assim, coletá-los, armazená-los e processá-los com as tecnologias e ferramentas corretas são atividades essenciais para possibilitar essa tomada de decisão através da inteligência com dados.
Tecnologias como NoSQL e Big Data são essenciais para proporcionar esse cenário descrito. Entenda mais como esse conjunto pode te auxiliar a lidar com os desafios relacionados a dados no seu dia a dia e garantir a qualidade e assertividade do ambiente de dados para tomada de decisão. Isso é o que você vai encontrar na trilha BigData & NoSQL.
Quarta-feira, 24 de Agosto de 2022
09h às 19h
ProMagno
Avenida Professora Ida Kolb - 513 /
Jardim das Laranjeiras - São Paulo - SP
ACESSO PRESENCIAL OU REMOTO COM TRANSMISSÃO ONLINE
Protocolo de Acesso Presencial
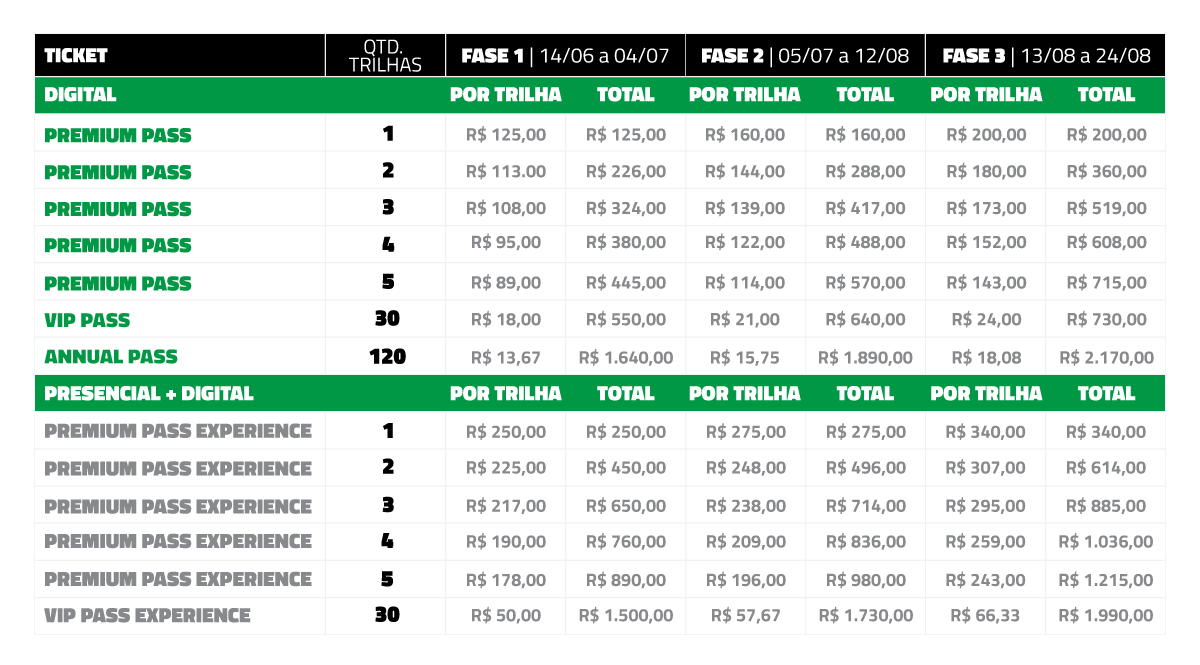
Valores para participação online:
1 trilha: de R$ 200 por R$ 125
2 trilhas: de R$ 400 por R$ 226
3 trilhas: de R$ 600 por R$ 324
* aproveite maior desconto até 04/07,
veja tabela completa
Valores para participação online:
1 trilha: de R$ 200 por R$ 160
2 trilhas: de R$ 400 por R$ 288
3 trilhas: de R$ 600 por R$ 417
* preço válido até 12/08,
veja tabela completa
Valores para participação online:
1 trilha: R$ 200
2 trilhas: de R$ 400 por R$ 360
3 trilhas: de R$ 600 por R$ 519
* preço válido até 24/08,
veja tabela completa
Valores para participação híbrida:
1 trilha: de R$ 340 por R$ 250
2 trilhas: de R$ 680 por R$ 450
3 trilhas: de R$ 1.020 por R$ 650
Valores para participação híbrida:
1 trilha: de R$ 340 por R$ 275
2 trilhas: de R$ 680 por R$ 496
3 trilhas: de R$ 1.020 por R$ 714
Valores para participação híbrida:
1 trilha: R$ 340
2 trilhas: de R$ 680 por R$ 614
3 trilhas: de R$ 1.020 por R$ 885
| Horário | Conteúdo |
|---|---|
| 07:45 às 08:55 | Recepção dos Participantes |
| 08:45 às 09:45 | Abertura do evento e mini keynotes |
| 09:50 às 10:30 |
KEYNOTE DO EVENTO
Reflexões do que aprendi em mais de 15 anos de carreira em desenvolvimento de softwareLoiane Groner(online) A carreira de uma pessoa que trabalha na área de desenvolvimento de software tem altos e baixos. Aprender com pessoas que trilharam os mesmos passos antes da gente é fundamental para ter uma carreira de sucesso. Porém, é importante também compartilhar o contexto para confirmar se os conselhos também se aplicam para nós. Nessa palestra, irei compartilhar algumas dicas do que aprendi trabalhando com desenvolvimento de software por 15+ anos, tanto na área de hard skills (técnica), quanto em soft skills.
|
| Horário | Conteúdo |
|---|---|
| 10:35 às 10:50 |
Abertura da trilha pela coordenação
Aqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
| 10:55 às 11:30 |
Desmitificando os formatos de tabelas modernos do seu Data Lake: Hudi, Delta Lake e IcebergLuiz Paulo Rocha YanaiVocê sabe qual a diferença entre o Apache Hudi, Delta Lake e Apache Iceberg? Sabe para que eles servem e como podem ajudá-los a otimizar custo e entregar features de compliance a LGPD? Venham participar desta sessão e descubram! 
|
| 11:40 às 12:15 |
Aplicações baseadas em Tempo-Real com Cassandra e PulsarSAMUEL HENRIQUE MATIOLICada vez mais as aplicações tem que resolver múltiplos processos instantaneamente e em larga escala. E aí, como armazenar e movimentar todos estes dados? Nesta palestra vamos abordar como usar o Apache Cassandra e Apache Pulsar para suportar escalabilidade de dados integrado à mensageria para atender aplicações NoSQL e usuários em tempo-real. 
|
| 12:25 às 13:00 |
NoSQL over Containers: Utilizando o Kubernetes para escalar bancos de dados NoSQLWilliam Lino OliveiraNesta sessão veremos na prática como utilizar o poderoso Kubernetes para provisionar e escalar infraestruturas de bancos de dados NoSQL como Redis, Cassandra, RavenDB e outros. Varios vendors de bancos de dados em cloud (PaaS) já estão utilizando Kubernetes como engine computacional para provisionar e escalar sua infraestrutura. 
|
| 13:05 às 14:05 |
Intervalo para almoço
Uma excelente oportunidade de todas as pessoas no evento interagirem e trocarem ideias, colaboradores, empresas patrocinadoras e apoiadoras, palestrantes e coordenadores. |
| 14:10 às 14:20 |
Abertura da trilha pela coordenação
Aqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
| 14:25 às 15:00 |
Migrando 1 Bilhão de DocumentosCarlos Eduardo Nunes Medina Martinez / Rodrigo FonsecaVamos falar sobre como nossa arquitetura foi evoluindo ao longo do tempo para lidar com volumes cada vez maiores de documentos até culminar com nossa primeira migração de mais de 1 bilhão de documentos e como isso se tornou uma tarefa recorrente e trivial para o time. 

|
| 15:15 às 15:50 |
Clean code em SQL - levando seu código a outro patamarAndrieli Campagnaro / Lucas José Harmatiuk da SilvaJá está mais do que na hora de falarmos sobre legibilidade de código em SQL. Muito se fala sobre clean code no desenvolvimento de software, mas quase nunca se fala sobre isso nas consultas SQL. O resultado é que muitas vezes temos códigos complexos escritos em SQL que demandam um tempo absurdo até entendermos o que ele faz. E o Uncle Bob destaca muito bem no livro clean code: nós passamos mais tempo lendo código do que escrevendo. Então, a ideia é trazer os conceitos de clean code para o mundo de SQL, para que possamos escrever códigos mais legíveis. Quanto mais simples de ler o código, mas rápida é nossa atuação em resolver o problema. 

|
| 15:55 às 16:30 |
Arquitetura LakehouseMarcus BittencourtUm novo paradigma de construção de arquitetura para plataformas de dados. Vamos falar sobre como implementar um Lakehouse sem ferramentas auxiliares, como aplicar este conceito de Lakehouse em um ambiente modernizando a arquitetura e preparando a plataforma de dados para o futuro e escalabilidade da empresa garantindo Democratização de dados e acelerando Data Driven. 
|
| 16:40 às 17:15 |
Processando um bilhão de mensagens por mês usando Open SourceIvan StoievPara conseguir levar informação correta e em tempo real para mais de 40k veículos em campo para gestores de frota, a Cobli processa mais de um bilhão de mensagens por mês em sua stack de IoT. Tudo isso usando software Open Source. Nessa palestra, faremos um overview desse ecossistema de coração aberto, elencando o que há de bom e ruim e os resultados concretos nos mais de 4 anos de sua evolução. Bora conhecer uma solução real de processamento de dados em larga escala "near real-time"? Palestrante: Ivan Stoiev - Engenheiro da computação com mais de 20 anos de experiência em TI - Atuou durante 17 anos no mercado mobile como "full stack" - Há três anos, é Especialista SRE na Cobli 
|
| 17:25 às 17:55 |
Networking e Visitação a Stands
Intervalo para fazer networking e conhecer os estandes do evento. |
| 18:05 às 19:05 |
Modern Data Stack - Desafios atuais para a implementação e manutenção de arquiteturas de Big Data e NoSQLMarcus BittencourtPainel desta Trilha
|
| Horário | Conteúdo |
|---|---|
| 19:15 às 19:50 |
Encerramento
Após a apresentação de resultados do dia, no palco da Stadium, muitos sorteios fecharão o dia. |






















































 Cícero Moura
Cícero Moura
 Lourenço Taborda
Lourenço Taborda
 Ricardo Martinelli de Oliveira
Ricardo Martinelli de Oliveira
 Sulamita Mara Dantas
Sulamita Mara Dantas