Trilha BIGDATA E NOSQL
Segundo a empresa de consultoria Gartner, até 2023, mais de 33% das grandes organizações terão analistas praticando inteligência de decisão (Decision Inteligence), que reúne várias disciplinas, incluindo gerenciamento e suporte à tomada de decisões. A importância da coleta de dados já está mais que comprovada. Com o crescimento da coleta de dados não estruturados, as tecnologias NoSQL e Big Data estão se desenvolvendo e se renovando. É preciso estar preparado e abraçar o futuro!
Data e Local
Quinta-feira, 2 de Dezembro de 2021
09h às 19h
ACESSO REMOTO COM TRANSMISSÃO ONLINE
Investimento
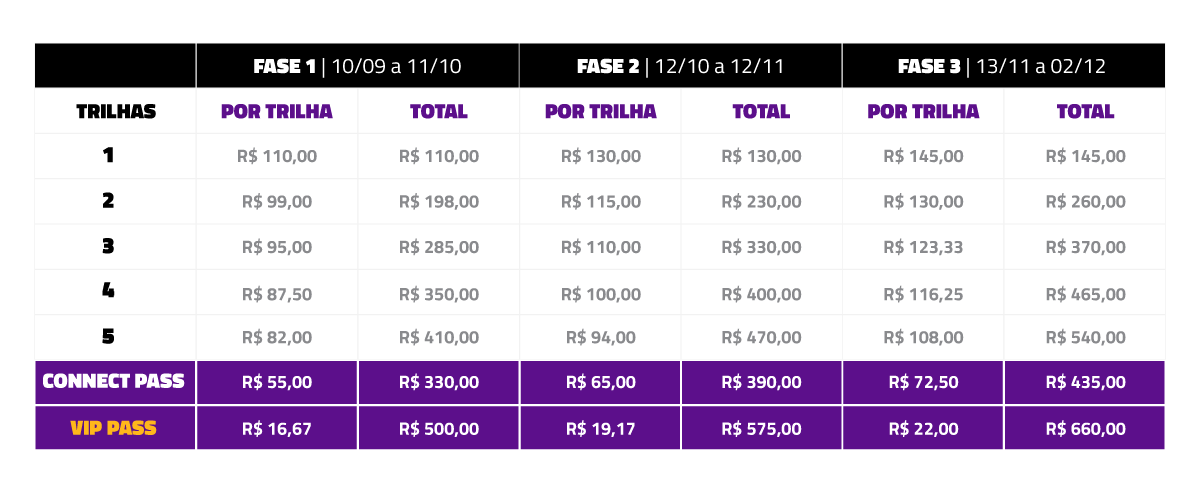
1 trilha: de R$ 145 por R$ 110
2 trilhas: de R$ 290 por R$ 198
3 trilhas: de R$ 435 por R$ 285
* preço válido até 11/10,
veja tabela completa
1 trilha: de R$ 145 por R$ 130
2 trilhas: de R$ 290 por R$ 230
3 trilhas: de R$ 435 por R$ 330
* preço válido até 12/11,
veja tabela completa
1 trilha: R$ 145
2 trilhas: de R$ 290 por R$ 260
3 trilhas: de R$ 435 por R$ 370
* preço válido até 02/12,
veja tabela completa
Como se inscrever













 Luana Costa
Luana Costa
 Sulamita Mara Dantas
Sulamita Mara Dantas
 Jéssica Álvares Jordão de Oliveira
Jéssica Álvares Jordão de Oliveira