Trilha DATA SCIENCE
Quando questionado sobre seu sucesso, Isaac Newton disse: ?Se eu vi mais longe do que os outros, foi por estar nos ombros de gigantes?. Nesta declaração profunda está um lembrete para todos nós: o progresso é feito com base em descobertas anteriores e no conhecimento daqueles que vieram antes de nós, e essa fala é especialmente verdadeira para nós que trabalhamos com CIÊNCIA de dados.
Nessa edição do TDC, trazemos a lembrança do quão importante é a pesquisa acadêmica e científica para a inovação e o desenvolvimento de soluções, principalmente no domínio da ciência de dados, para pavimentar nosso futuro. Aqui, vamos reunir pesquisadores, acadêmicos e cientistas que lidam com aspectos epistemológicos, teóricos, metodológicos e aplicados dentro da área, por meio da discussão de pesquisas em estado da arte, democratizando o conhecimento e compartilhando boas práticas com a comunidade.
Sempre temos a opção de encontrar um gigante e aprender com ele. Nesse processo, o conhecimento se forma e todos conseguem ver mais longe, à medida que abrimos novas portas para o que é possível. Venha nos ajudar a construir a ciência ? de dados, utilize nosso espaço para isso!
Data e Local
Quarta-feira, 1 de Dezembro de 2021
09h às 19h
ACESSO REMOTO COM TRANSMISSÃO ONLINE
Investimento
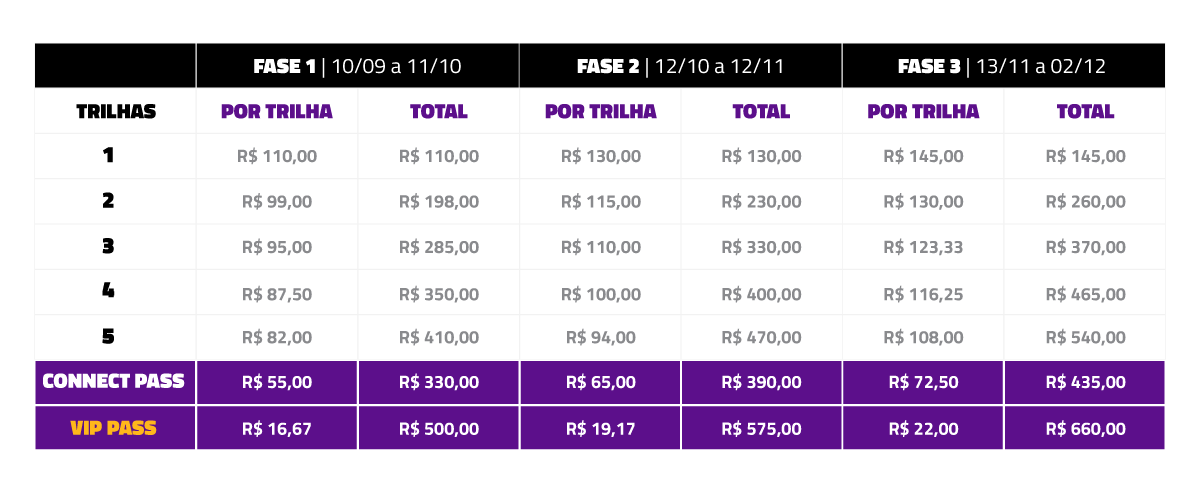
1 trilha: de R$ 145 por R$ 110
2 trilhas: de R$ 290 por R$ 198
3 trilhas: de R$ 435 por R$ 285
* preço válido até 11/10,
veja tabela completa
1 trilha: de R$ 145 por R$ 130
2 trilhas: de R$ 290 por R$ 230
3 trilhas: de R$ 435 por R$ 330
* preço válido até 12/11,
veja tabela completa
1 trilha: R$ 145
2 trilhas: de R$ 290 por R$ 260
3 trilhas: de R$ 435 por R$ 370
* preço válido até 02/12,
veja tabela completa
Como se inscrever
















 Fernanda Teixeira Dos Santos
Fernanda Teixeira Dos Santos
 Renata Cristina Gutierres Castanha
Renata Cristina Gutierres Castanha
 Diogenes Justo
Diogenes Justo