Data Science não é só o futuro, mas o presente!
Sabe por quê?
Hoje em dia podemos encontrar dados esperando para ser analisados e auxiliar na tomada de decisão em qualquer lugar! Empresas e organizações, curiosos, entusiastas em algum assunto, tudo e todos tem dados!
Não é a toa que Clive Humby, um matemático inglês afirmou que "Dados são o novo petróleo" ("Data is the new oil"). O mercado de dados está mais aquecido do que nunca - a estimativa é que mais de 60ZB (zettabytes - o equivalente a 6 trilhões de gigabytes!) já são gerados por ano pela humanidade.
E essa tendência veio para ficar! Com Big Data, Cloud Computing, Inteligência Artificial, e todas essas "buzzwords"...
E, a Ciência de Dados (ou Data Science) é onde esses dados são transformados em inteligência para tomada de decisões e basear um crescimento seguro e focado nos objetivos desejados.
A trilha Data Science do TDC Future traz especialistas da área para compartilhar com você o que está acontecendo e o que é "quente" no mercado, para se manter atualizado/a nestas tendências e oportunidades.
Participando desta trilha, você terá informações para gerar insights inovadores para sua carreira e dentro da sua organização.
Venha fazer parte do futuro dos dados, hoje.
Quinta-feira, 8 de Dezembro de 2022
09h às 19h
UniRitter
Rua Orfanotrófio, 555 /
Alto Teresópolis - Porto Alegre - RS
ACESSO PRESENCIAL OU REMOTO COM TRANSMISSÃO ONLINE
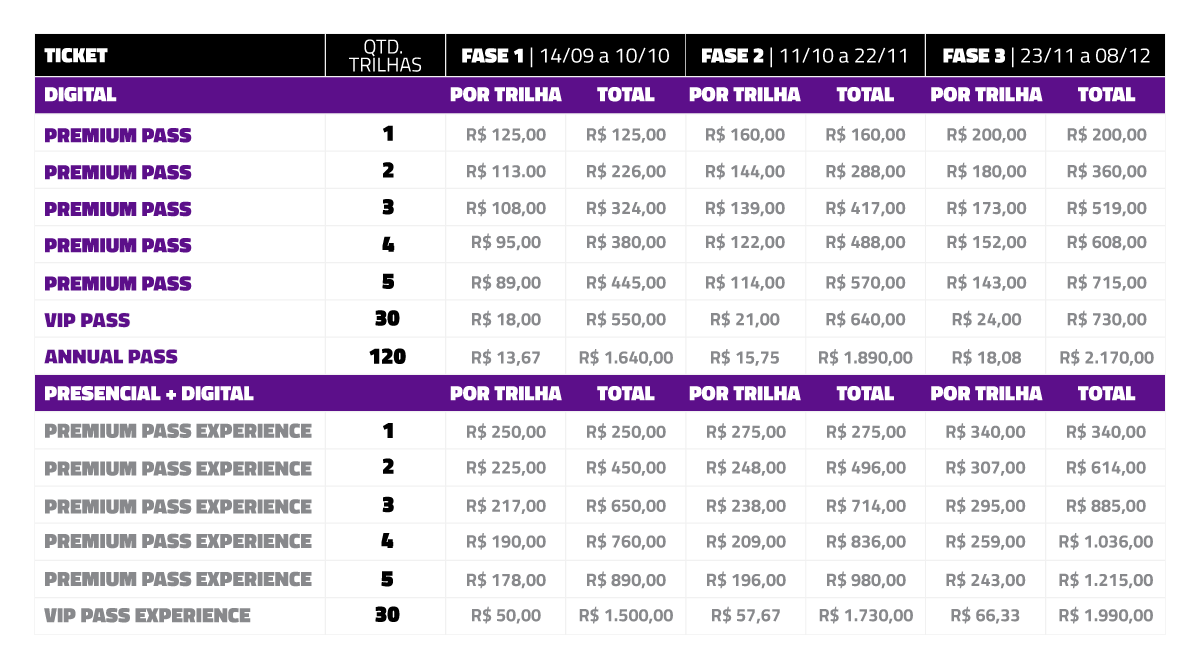
Valores para participação online:
1 trilha: de R$ 200 por R$ 125
2 trilhas: de R$ 360 por R$ 226
3 trilhas: de R$ 519 por R$ 324
* aproveite maior desconto até 10/10,
veja tabela completa
Valores para participação online:
1 trilha: de R$ 200 por R$ 160
2 trilhas: de R$ 360 por R$ 288
3 trilhas: de R$ 519 por R$ 417
* preço válido até 22/11,
veja tabela completa
Valores para participação online:
1 trilha: R$ 200
2 trilhas: R$ 360
3 trilhas: R$ 519
* preço válido até 08/12,
veja tabela completa
Valores para participação híbrida:
1 trilha: de R$ 340 por R$ 250
2 trilhas: de R$ 614 por R$ 450
3 trilhas: de R$ 885 por R$ 650
Valores para participação híbrida:
1 trilha: de R$ 340 por R$ 275
2 trilhas: de R$ 680 por R$ 496
3 trilhas: de R$ 1.020 por R$ 714
Valores para participação híbrida:
1 trilha: R$ 340
2 trilhas: R$ 614
3 trilhas: R$ 885
| Horário | Conteúdo |
|---|---|
| 07:45 às 08:55 | Recepção dos Participantes |
| 08:45 às 09:45 | Abertura do evento e mini keynotes |
| 09:50 às 10:30 |
KEYNOTE DO EVENTO
QUEM SOMOS - Mapa de Talentos Negros em TecnologiaAndreza RochaO AfrOya Tech Hub lançou a mais aprofundada pesquisa já realizada sobre talentos negros em tecnologia no Brasil. Um retrato de abrangência nacional que norteará com assertividade a realização de agendas afirmativas exclusivas para a população negra no ecossistema de tecnologia.

|
| Horário | Conteúdo |
|---|---|
| 10:35 às 10:50 |
Abertura da trilha pela coordenação
Aqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
| 10:55 às 11:30 |
Como criar um projeto de dados aplicado a CRM: dos dados brutos à implementaçãoWilliam BeckhauserHoje 89% das empresas competem apenas na qualidade do gestão de relacionamento com o cliente, ou CRM, e mais de 90% das empresas tem seus sistemas com falhas nos dados. É de suma importancia uma boa visão de onde, e para onde nossos clientes estão a caminhar. A implementação de um projeto de dados, quando bem feito, pode e trará aumento de receita para a empresa. O mais importante é deixar o projeto limpo, e com ferramentas (sempre a buscar alternativas open-source) que apoiem a escalabilidade e as mudanças que os estudos de CRM podem trazer ao longo da vida do negócio. 
|
| 11:40 às 12:15 |
Análise e reconhecimento de padrões de fraudes digitais com dados pessoais através de clusterização e redes de grafosLeonardo Valeriano Neri / Fernando Baptistella de Lima(online) A detecção de fraudes no meio digital é essencial em qualquer e-commerce e canal de vendas online, tendo grande aceleração na adoção por conta da pandemia. É importante descobrir características de transações/operações fraudulentas em meio a um grande volume de dados o quanto antes, afim de gerar alertas e evitar perdas financeiras. Mostraremos técnicas de clusterização para geração de grafos os quais podem ser usados para modelar caracterísiticas de um comportamento fraudulento. Será apresentado um caso implementado com a biblioteca NetworkX para modelar comportamento fraudulento no contexto de dados pessoais, e exibindo o grafo que explica o modus operandi das fraudes. 

|
| 12:25 às 13:00 |
Você não precisa de outro dashboardAna Bertol?Nós queremos que todos saibam o que está acontecendo. Faz um dashboard aí pra todo mundo poder acessar?. Se você ainda não ouviu essa frase é porque você é a pessoa falando ela. E assim, nada contra fazer dashboards. Até tenho amigos que fazem (inclusive eu mesma adoro). Mas é um erro apostar que dashboards são a solução para criar uma cultura data driven, ou que é possível criar um dashboard que vai resolver os problemas de todo mundo dentro da organização. Vamos conversar sobre como criar uma solução analítica pensando primeiro nas pessoas que vão usar ela, e como esse é o caminho para criar produtos de dados mais efetivos e que não serão abandonados depois de pouco tempo de uso. 
|
| 13:05 às 14:05 |
Intervalo para almoço
Uma excelente oportunidade de todas as pessoas no evento interagirem e trocarem ideias, colaboradores, empresas patrocinadoras e apoiadoras, palestrantes e coordenadores. |
| 14:10 às 14:20 |
Abertura da trilha pela coordenação
Aqui os coordenadores se apresentam e fazem uma introdução para a trilha. |
| 14:25 às 15:00 |
Data Science e a importância das informações de contextoJorge Cristhian Chamby DiazDe acordo com a revista Forbes, 87% dos projetos de Data Science (DS) jamais chegam a produção. Dentro das razões para esses cases de insucesso (por exemplo: gap de habilidades técnicas e de negócios; gaps de gerações tecnológicas; metas indefinidas, etc.), este trabalho está focado na "integração pobre de dados". Projetos de DS enriquecem seus dados cruzando informações de diversos sistemas, e muitas vezes ignoram dados que indiretamente afetam muito o desempenho do modelo preditivo, as "informações de contexto" (informação semântica que pode ser associada a observações, tais como clima, eventos, etc). Neste trabalho esta problemática é abordada, e são apresentados dois cases de sucesso. 
|
| 15:15 às 15:50 |
Framework Humano-Computacional para Preparação Acelerada de DadosGilsiley Henrique DarúCom o advento da pandemia e com as restrições impostas em muitos países, a área de e-commerce cresceu significativamente. Com isto, as empresas tiveram que aprimorar suas plataformas de comércio eletrônico. Plataformas estas que precisam entregar uma experiência adequada para o usuário de forma simples e objetiva. No entanto os usuários encontram dificuldades na busca de informacões adequadas, o que gera para as plataformas um trabalho de classificacão e preparacão de dados. É possível aplicar técnicas de classificação, assim, o objetivo desta palestra é apresentar técnicas que permitam classificar somente os dados necessários para alimentação os algoritmos de classificação. 
|
| 15:55 às 16:30 |
Uso de Clusterização e Deep Learning para separação de 'Speaker' em conversas de áudioJoão Vitor Rafare / Diego Hiroshi SetoProblemas de Machine Learning e Data Science que envolvem áudio são amplamente pesquisados hoje em dia. Entre eles, um específico é a Diarização de Locutor (Speaker Diarization), que é a tarefa de separar quando que cada locutor está falando em um áudio. Ela é especialmente complexa porque envolve outros 2 problemas diferentes: A detecção de fala e não-fala (Speech Activity Detection) e a extração de características (Speech Embedding). O objetivo desta palestra é introduzir conceitos básicos de diarização de locutor e elucidá-los através de um caso particular que utiliza CNN e clusterização. 

|
| 16:40 às 17:15 |
Garantia de autenticidade de conteúdos web com BlockChainMeirylene AvelinoO objetivo da talk é introduzir uma proposta de uso de Blockchain para registros de conteúdos Web, com o objetivo de permitir a auditabilidade quanto a autenticidade e integridade de versão, além de possibilitar a consulta do histórico de todos os registros realizados para uma dada URL. 
|
| 17:25 às 17:55 |
Networking e Visitação a Stands
Intervalo para fazer networking e conhecer os estandes do evento. |
| 18:05 às 19:05 |
Cultura Data Driven: como superar desafios para implantar na minha empresa?Luiz Paulo Oliveira Paula / Fernanda Machado / Geisa Amador RochaPainel de Discussão desta Trilha



|
| Horário | Conteúdo |
|---|---|
| 19:15 às 19:50 |
Encerramento
Após a apresentação de resultados do dia, no palco da Stadium, muitos sorteios fecharão o dia. |





































 Csilla Szanto
Csilla Szanto
 Eduardo Ribeiro Heitor
Eduardo Ribeiro Heitor
 Rita Carolina Alamino
Rita Carolina Alamino
 Adriana Weingart
Adriana Weingart